Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
# Brief History
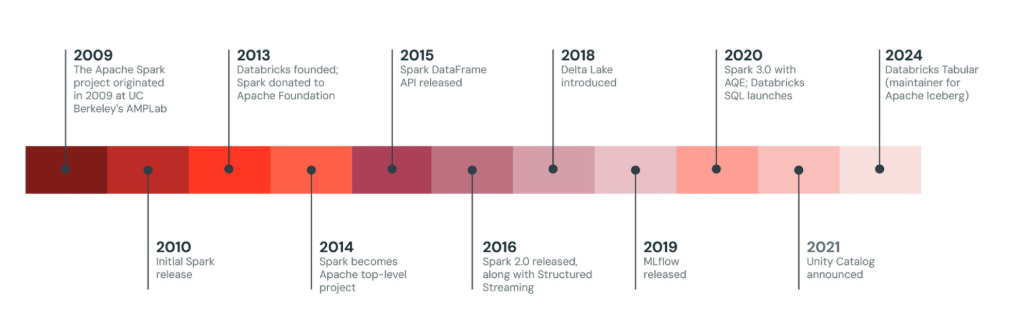
Originally developed at the University of California, Berkeley’s AMPLab starting in 2009, in 2013, the Spark codebase was donated to the Apache Software Foundation, which has maintained it since.
# Overview
Sparks architecture is based on the concept of resilient distributed dataset (RDD), a immutable, distributed collection of objects that can be operated on in parallel over a cluster. The Dataframe API was released as an abstraction on top of the RDD, followed by the Dataset API.
In Spark 1.x, the RDD was the primary application programming interface (API), but as of Spark 2.x use of the Dataset API is encouraged even though the RDD API is not deprecated. The RDD technology still underlies the Dataset API
RDDs were developed in 2012 in response to the limitations in the Map Reduce {continue later}
Inside Apache Spark the workflow is managed as a directed acyclic graph (DAG). Nodes represent RDDs while edges represent the operations on the RDDs.
# Spark Core
# Outline
The below content is mapped according to Databricks Certified Associate Developer for Apache Spark certification by Databricks along with Apache Spark Documentation.
Furthermore I will be using the following courses provided by Databricks for free.
- Introduction to Apache Spark™
- Developing Applications with Apache Spark™
- Stream Processing and Analysis with Apache Spark™
- Monitoring and Optimizing Apache Spark™ Workloads on Databricks
| Section | Topic | Key Concepts & Components |
|---|---|---|
| 1. Architecture | Core Infrastructure | Driver: Orchestrates execution. Worker/Executors: Runs tasks. Cluster Manager: Allocates resources. |
| Data Structures | RDD: Low-level API. DataFrame/Dataset: High-level structured APIs. | |
| Execution | Lazy Evaluation: Plan created, execution delayed until an Action. Hierarchy: Application → Job → Stage → Task. | |
| Memory & Storage | Caching/Persistence: Storing data in memory/disk. Storage Levels: MEMORY_ONLY, DISK_ONLY, etc. | |
| 2. Spark SQL | Data Sources | Reading/Writing: JDBC, CSV, JSON, ORC, Parquet, and Delta Lake. |
| Save Modes | append, overwrite, errorIfExists, ignore. | |
| Views & Tables | createOrReplaceTempView for SQL access; saving to persistent tables with partitionBy. | |
| 3. DataFrame API | Basic Operations | select, filter, withColumn, drop, rename, explode. |
| Aggregations | groupBy, count, approx_count_distinct, mean, summary. | |
| Joins | Inner, Left, Cross, Union/Union All, and Broadcast Joins (small table in memory). | |
| Functions | UDFs: Custom logic. Date/Time: Converting Unix epoch, extracting year/month. | |
| Shared Variables | Broadcast Variables: Read-only data on all nodes. Accumulators: Write-only counters. | |
| 4. Tuning | Partitioning | Coalesce: Decreasing partitions. Repartition: Increasing/reshuffling partitions. |
| Optimization | AQE (Adaptive Query Execution): Adjusts plans at runtime. Data Skew: Handling uneven data distribution. | |
| Monitoring | Analyzing Driver/Executor logs for OOM (Out of Memory) errors and resource usage. | |
| 5. Streaming | Logic | Micro-batching: Processing data in small increments. Exactly-once: Guarantees no data loss/duplication. |
| State Management | Watermarking: Handling late data. Deduplication: Removing duplicates in the stream. | |
| Output Modes | Append, Complete, Update. | |
| 6. Deployment | Spark Connect | Decouples client applications from the Spark Server for better stability and remote access. |
| Modes | Local: Single machine. Client: Driver on local. Cluster: Driver on the cluster. | |
| 7. Pandas API | Scaling Pandas | Run Pandas code on Spark distributed clusters using pyspark.pandas. |
| Pandas UDFs | Vectorized UDFs: Higher performance using Apache Arrow for data transfer. |