OLAP (Online Analytical Processing)
# What is OLAP?
OLAP stands for Online Analytical Processing. It’s a powerful tool for multidimensional business data analysis, offering complex calculations, trend analysis, and advanced data modeling capabilities.
An OLAP Cube is a specialized multidimensional database, optimized for data warehouse and OLAP applications. It stores data in a multi-dimensional form, primarily for reporting. In these cubes, data (measures) are organized by dimensions.
# Modern vs. Traditional OLAP Cubes
Traditional OLAP systems are built around centralized data warehouses where data is carefully structured in advance using schemas like star or snowflake models. These systems rely on pre-aggregated OLAP cubes, which make querying very fast but limit flexibility. Data must go through ETL (Extract, Transform, Load) processes before it can be analyzed, meaning the structure is defined before storage (schema-on-write). While this approach works well for stable and predictable queries, it struggles with scalability and handling large or diverse datasets. Tools like Microsoft SQL Server Analysis Services and IBM Cognos are typical examples of traditional OLAP technologies.
In contrast, modern OLAP systems are designed for big data and cloud environments, offering far greater flexibility and scalability. Instead of relying on rigid cubes, they use data lakes or lakehouse architectures where data can be stored in raw form and analyzed when needed. This approach follows ELT (Extract, Load, Transform), allowing schema to be applied at query time (schema-on-read). Modern OLAP systems support both structured and unstructured data and can handle real-time or near real-time analytics. They scale horizontally across distributed systems, making them ideal for large-scale data processing. Technologies such as Apache Spark, Snowflake, and Google BigQuery are widely used in this modern approach, enabling faster insights and more dynamic analysis compared to traditional methods.
| Feature | Traditional OLAP | Modern OLAP |
|---|---|---|
| Storage | Data Warehouse | Data Lake / Lakehouse |
| Data Handling | Structured only | Structured + semi/unstructured |
| Processing | Pre-aggregated cubes | On-demand computation |
| Pipeline | ETL | ELT |
| Schema | Schema-on-write | Schema-on-read |
| Scalability | Limited, expensive | Highly scalable |
| Speed | Fast for fixed queries | Fast + flexible |
| Real-time | Mostly batch | Supports streaming |
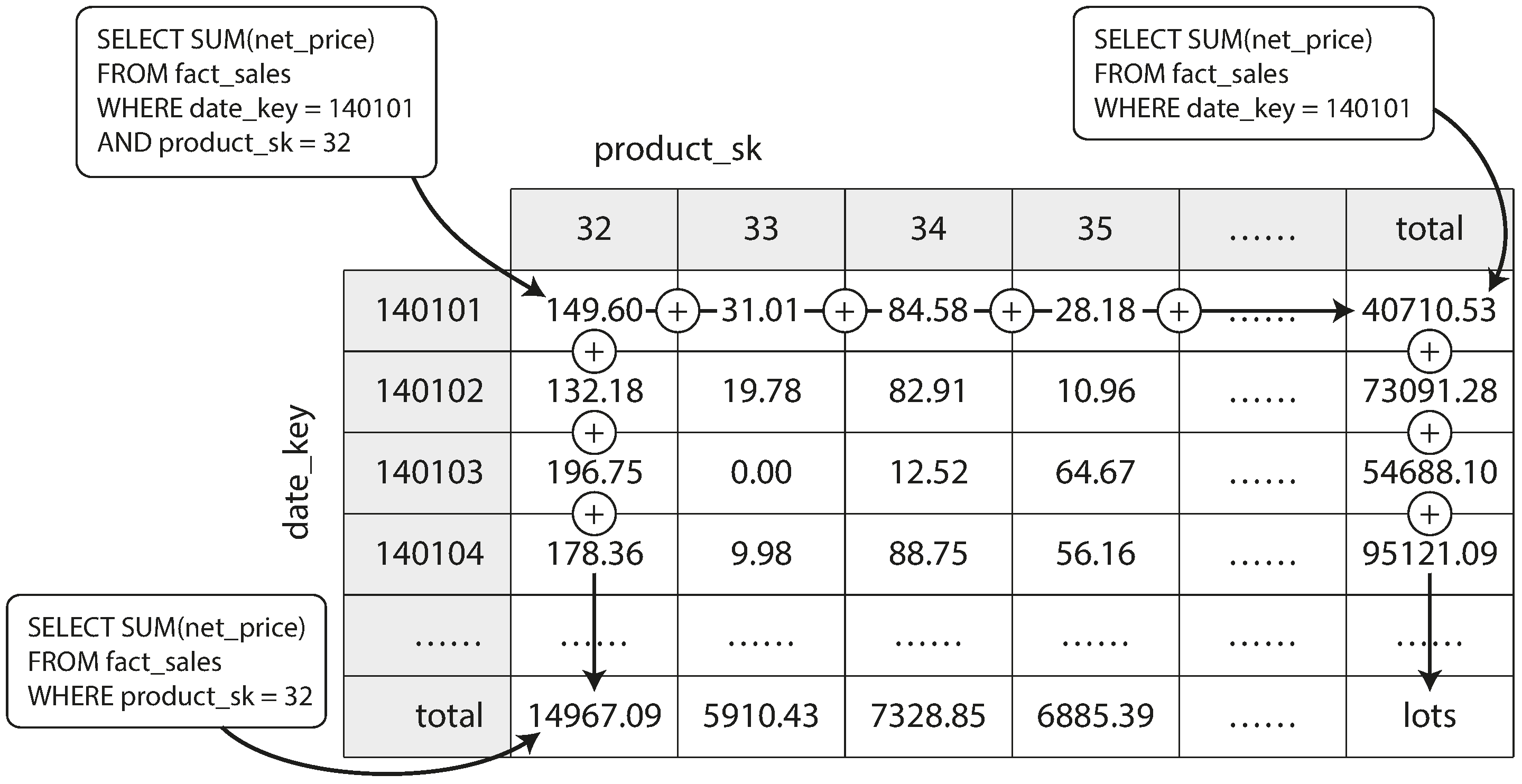
# OLAP Cubes
Data warehouse queries often involve an aggregate function, such as COUNT, SUM, AVG, MIN, or MAX in SQL. If the same aggregates are used by many different queries, it can be wasteful to crunch through the raw data every time. Why not cache some of the counts or sums that queries use most often?
One way of creating such a cache is a Materialized view. In a relational data model, it is often defined like a standard (virtual) view: a table-like object whose contents are the results of some query. The difference is that a materialized view is an actual copy of the query results, written to disk, whereas a virtual view is just a shortcut for writing queries.
When you read from a virtual view, the SQL engine expands it into the view’s underlying query on the fly and then processes the expanded query.When the underlying data changes, a materialized view needs to be updated, because it is a denormalized copy of the data. The database can do that automatically, but such updates make writes more expensive, which is why materialized views are not often used in OLTP databases. In read-heavy data warehouses they can make more sense (whether or not they actually improve read performance depends on the individual case).
A common special case of a materialized view is known as a data cube or OLAP cube. It is a grid of aggregates grouped by different dimensions.