# What Is Data Modeling?
In the context of data engineering, data modeling creates a structured representation of your organization’s data. This representation, often illustrated visually, helps understand the relationships, constraints, and patterns within the data and serves as a blueprint for gaining business value in designing data systems, such as data warehouses, lakes, or any analytics solution.
In its most straightforward form, data modeling is how we design the flow of our data such that it flows as efficiently and in a structured way, with good data quality and as little redundancy as possible.
# Brief History of Data Modeling
| Era | Time Period | Key Developments | Key People / Concepts |
|---|---|---|---|
| Early Data Management | 1960s–1970s | First databases and data models emerged; hierarchical and network models dominated; BI & data warehousing in infancy | Hierarchical Model, Network Model |
| Relational Revolution | 1980s | Relational model transformed data management; structured querying and table-based design; rise of ERDs | Edgar F. Codd, Relational Model, ERD |
| Data Warehousing & BI | 1990s | Growth of BI and data warehousing; structured analytical systems; focus on reporting and decision-making | Ralph Kimball (Dimensional Modeling), Bill Inmon (Top-down approach) |
| Big Data Expansion | 2000s | Explosion of data volume, variety, velocity; web & social media data; new storage systems | Hadoop, NoSQL, Data Lakes |
| Modern Data Engineering | 2010s–Present | Cloud computing, real-time processing, ML integration; complex and scalable data ecosystems | Cloud Data Warehouses, Streaming, Advanced Analytics |
# Conceptual, Logical & Physical Data Models
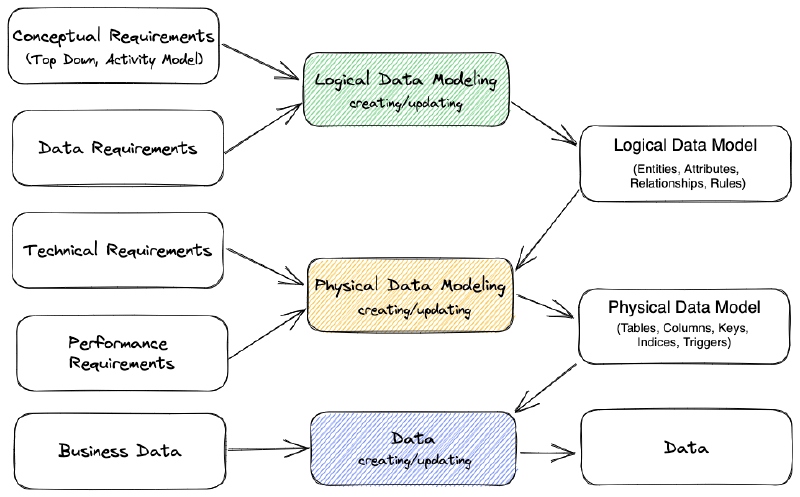
Conceptual → Logical → Physical Data Models
The conceptual model represents a high-level view (top-down of the data), the logical model provides a more detailed representation of data relationships, and the physical model defines the actual implementation in the database or data storage system (bottom-up).
Data modeling can be applied at different levels and contains more than just modeling. Besides the conceptual, logical, and physical data model, you can model your source OLTP database, warehouse, BI tool, and ML features. More importantly, we discuss further in this article the overall data modeling across the organization.
In the end, each layer of the Data Engineering Lifecycle can be modeled. To name just a few:
- Generation or source database: Model the entities of your application’s source database, and normalize tables to its Third normal form (3NF). Choose the best features of the database of choice.
- Data integration and ETL processes: Define the source-to-target mappings, transformations, and data cleansing rules to move and consolidate data from multiple sources into a data warehouse or other central storage.
- Analytical Layer
- Data warehouse: Creation of denormalized or multi-dimensional models, such as star or snowflake schemas, enabling efficient querying and data aggregation.
- Data lake: Applied to create a consistent structure, catalog, and metadata management strategy for diverse and often unstructured data sources to improve data discovery, governance, and accessibility.
- Data Lakehouse: A unified analytical approach that combines the scalability of data lakes with the performance and structure of data warehouses, enabling both BI and machine learning workloads on a single platform.
- BI tools and reporting (Presentation level): Designing the data structures, aggregations, and calculations used in reporting and visualization tools. Building the presentation layer may involve creating Semantic Layers, such as data cubes, that simplify business users’ access to the underlying data.
- Machine learning and AI: Feature engineering, normalization, and data encoding to ensure compatibility with various algorithms and tools.
Other Important Types of Data Modeling (Based on Use Case)
Beyond conceptual, logical, and physical models, data engineering also involves specialized modeling approaches tailored to different systems and workloads.
# Normalization (OLTP Systems)
Normalized data modeling is used in transactional systems (OLTP) where data integrity and consistency are critical. It follows normalization principles such as First, Second, and Third Normal Form (1NF, 2NF, 3NF) to eliminate redundancy and ensure accurate data storage. This approach is well-suited for applications that involve frequent inserts, updates, and deletes.
# Dimensional Modeling (Analytics)
Dimensional modeling is primarily used in analytical systems such as data warehouses to support reporting and decision-making. It organizes data into fact tables (containing measurable metrics) and dimension tables (containing descriptive attributes). Common schema designs include the star schema and snowflake schema. This approach is optimized for fast query performance and efficient aggregation rather than strict normalization.
# Data Vault Modeling
Data Vault modeling is a modern approach designed for scalable and flexible data warehousing. It is particularly effective for handling historical data and adapting to changing business requirements. The model is built using three core components: hubs (which store unique business keys), links (which represent relationships between entities), and satellites (which store descriptive attributes and historical changes).